Alignment of spatial transcriptomics data¶
This tutorial show how to use the AlignmentProblem for aligning spatial transcriptomics data.
When multiple spatial transcriptomics datasets are generated, it is desirable to integrate them and align them in the same coordinate system. moscot reimplements the method firstly introduced in PASTE [Zeira et al., 2022]to align spatial transcriptomics data, integrating both gene expression and spatial similarity.
For the purposes of this tutorial, we will show the application of the AlignmentProblem on simulated data.
Note
For this tutorial, Squidpy is needed for spatial data plotting. You can either install it with:
pip install squidpyorpip install moscot[spatial]as an optional dependency ofmoscot
See also
If the spatial coordinates are only available for one dataset, see Mapping gene expression in space on how to transfer gene expression from single-cell data to spatial data.
Imports and data loading¶
import warnings
warnings.simplefilter("ignore", UserWarning)
warnings.simplefilter("ignore", FutureWarning)
import moscot as mt
from moscot import datasets
from moscot.problems.space import AlignmentProblem
import scanpy as sc
import squidpy as sq
Simulate data using simulate_data().
adata = datasets.sim_align()
adata
AnnData object with n_obs × n_vars = 1200 × 500
obs: 'batch'
uns: 'batch_colors'
obsm: 'spatial'
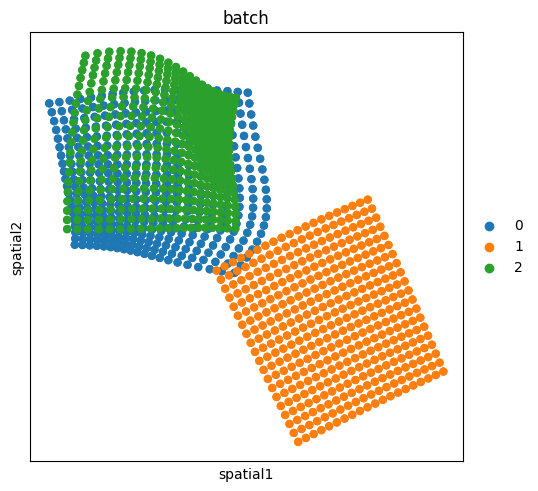
The adata consits of 3 different slides (batches), each having 400 cells.
sq.pl.spatial_scatter(adata, shape=None, library_id="batch", color="batch")
Aligning spatial transcriptomics¶
With moscot, it is possible to learn a cross-dataset mapping by leveraging Fused Gromov-Wasserstein (FGW) optimal transport [Vayer et al., 2018]. A basic description of the algorithm is the following:
Given a set of observations that share some features in the metric space, and some other features in different metric spaces, the FGW method aims at finding the optimal matching between these two set of observations, based on both shared and unique features. In our case:
the “shared” metric space could be the one defined by a set of genes that is measured across spatial transcriptomics data.
the “unique” metric spaces are the spatial coordinates, which are unique for each single slide.
Prepare the AlignmentProblem¶
The AlignmentProblem exposes the FGW algorithm in a user-friendly API. First, we need to prepare() the problem. In this particular case, we need to pay attention to the policy parameter. The available policies are:
'star': if we wish to align all slides to a reference slide.'sequential'(default): if we wish to align each slide to the subsequent one, in case we have a sequence of slides.
The choice of the policy varies with the use cases, for the sake of this tutorial we will showcase the 'sequential' policy.
ap = AlignmentProblem(adata=adata)
ap = ap.prepare(batch_key="batch", policy="sequential")
INFO Ordering Index(['400', '401', '402', '403', '404', '405', '406', '407', '408', '409',
...
'390-1', '391-1', '392-1', '393-1', '394-1', '395-1', '396-1', '397-1',
'398-1', '399-1'],
dtype='object', length=1200) in ascending order.
INFO Computing pca with `n_comps=30` for `xy` using `adata.X`
INFO Normalizing spatial coordinates of `x`.
INFO Normalizing spatial coordinates of `y`.
INFO Computing pca with `n_comps=30` for `xy` using `adata.X`
INFO Normalizing spatial coordinates of `x`.
INFO Normalizing spatial coordinates of `y`.
INFO Normalizing spatial coordinates of `x`.
INFO Normalizing spatial coordinates of `y`.
INFO Computing pca with `n_comps=30` for `xy` using `adata.X`
INFO Normalizing spatial coordinates of `x`.
INFO Normalizing spatial coordinates of `y`.
Solve the AlignmentProblem¶
ap = ap.solve()
INFO Solving `2` problems
INFO Solving problem OTProblem[stage='prepared', shape=(400, 400)].
No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
INFO Solving problem OTProblem[stage='prepared', shape=(400, 400)].
In the previous cells, we both prepared and solved the problems using the default arguments. However, it’s important to take into consideration the alpha value, which balances the weight of each loss (“unique” vs. “shared” spaces). With alpha close to \(0\), the “shared” space loss is weighted more, with alpha close to \(1\), the “unique” space loss is balanced more. We suggest to try various values that might be more fitting to the specific use case.
Analysis of the transport plans¶
Solving the OT problem means that we computed the optimal transport plans between the various slides. We can now use it to align our datasets. There are two methods to perform the alignment:
'warp'(default): which warps the spatial coordinates of the source slide to the target slide.'affine': which computes the affine transformation from the transport map and simply shift and rotate the coordinates preserving the original space.
Let’s for instance warp the slides to a reference slide of choice. To do so, we need to pass as reference the key corresponding to the slide of choice. When using the align(), by default it modifies the input AnnData object in place by saving the transformed coordinates in a new obsm key.
Warping alignment¶
ap.align(reference="2", key_added="spatial_warp")
sq.pl.spatial_scatter(
adata, shape=None, spatial_key="spatial_warp", library_id="batch", color="batch"
)
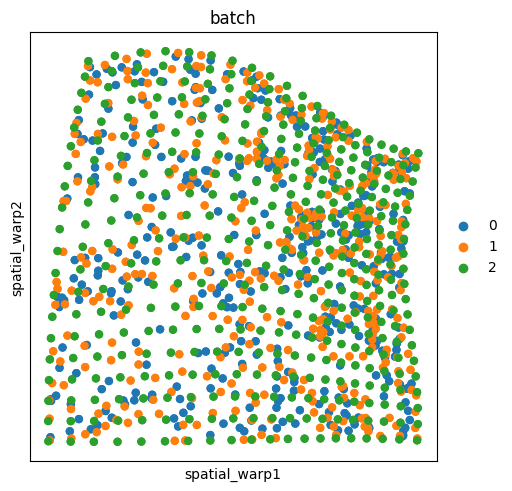
We can appreciate that the slides '0' and '1' have been warped to match the coordinate system of the slide '2'. Nevertheless, the results do not seem particularly good, since the points are scattered around.
One explanation for this is that the gene expression variability is driving the computed transportation plan, and it might not be representative of the spatial structure of the data (a simple grid in this case). It should be noted that the 3 simulated slides have been generated with random gene expression data.
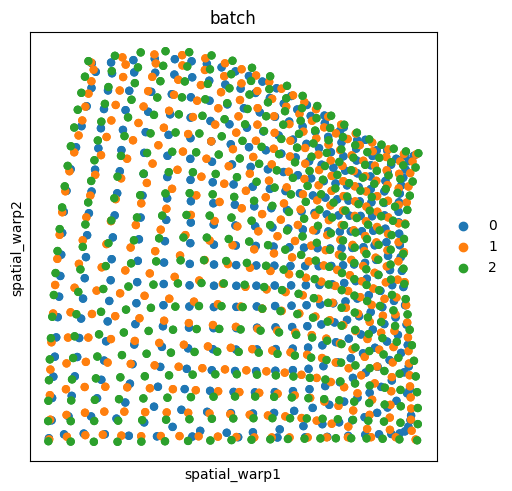
Let’s try to solve the problems again but this time with a higher alpha value in order to get a more coherent alignment.
ap = ap.solve(alpha=0.9)
ap.align(reference="2", key_added="spatial_warp")
sq.pl.spatial_scatter(
adata, shape=None, spatial_key="spatial_warp", library_id="batch", color="batch"
)
INFO Solving `2` problems
INFO Solving problem OTProblem[stage='solved', shape=(400, 400)].
INFO Solving problem OTProblem[stage='solved', shape=(400, 400)].
Affine alignment¶
Lastly, we will experiment with the affine alignment method and also change the reference slide to '1'.
ap.align(reference="1", mode="affine", key_added="spatial_affine")
sq.pl.spatial_scatter(
adata, shape=None, spatial_key="spatial_affine", library_id="batch", color="batch"
)
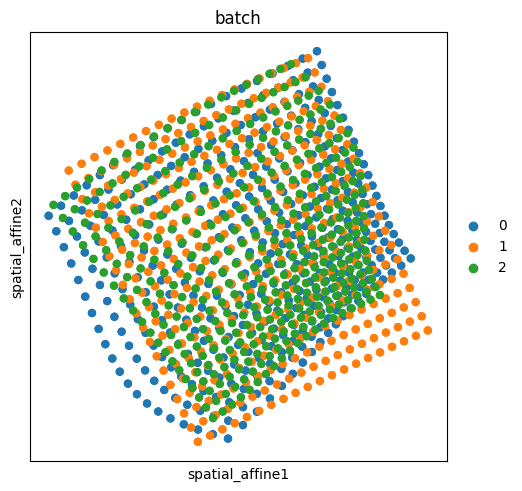
We can appreciate how the slides have now been projected on the same reference coordinates of slide '1' yet without warping the original space. We can also plot the original space to appreciate the result.
sq.pl.spatial_scatter(adata, shape=None, library_id="batch", color="batch")